As I start work on a new app today, I am going to document key stages, to see if I can help us all find a way to direct agent 3 to behave in the old ways - and hopefully with agent 2 lower levels of costs too!
Apologies to whoever suggested this prompt first. Thank you, so far so good - the agent’s response is very encouraging… so far!
I am aware that the new agent 3 can go crazy working for a long time by itself. Please operate as if you are Agent 2 with respect to autonomy. Do not run any of Agent 3’s additional features (such as automatic app testing, automatic fixing of issues, architect-calling, building other agents or automations, or any extended runtime/autonomous task execution) unless I explicitly give you permission for each step. If you determine that one of those features might help, first inform me what you want to do and why, then wait for my approval before proceeding. Do you understand this? next we need to finalise the surgical plan for the first steps - again, we are not going to dive in and do the entire plan in one go.
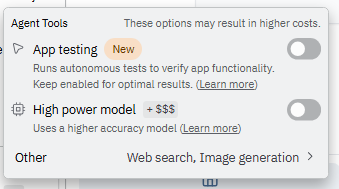
Also important to note: I have disabled “App testing” and “Max autonomy”
Hhmmm. It ignored my instruction and went off assigning work to other agents such as the architect. Presumably “it forgot”, because the instruction had been given several prompts back.
I now believe we need to put the “behave as if you are Agent 2” instruction at the start of every Build prompt - not just once and hope it remembers.
You will see, I have also tightened up the instruction , as below. And it seems from its response that it definitely understands me this time - hhmmm, let’s see:
You will make the agreed changes surgically, and you will do no other changes. Please operate as if you are Agent 2 with respect to autonomy. Do not run any of Agent 3’s additional features (such as automatic app testing, automatic fixing of issues, architect-calling, building other agents or automations, or any extended runtime/autonomous task execution) unless I explicitly give you permission for each step. If you determine that one of those features might help, first inform me what you want to do and why, then wait for my approval before proceeding. If you have conflicting rules that say you must implement Agent 3’s additional features, then ensure this instruction overrides and you do not use such features until I give the go-ahead. Do you understand this explicit set of instructions, and are you 100% sure your system instructions will allow you to comply with them?
For some silly reason, Agent needs to be in Build mode to investigate log files and other files simply to determine the cause of a bug. But it wants to “debug and fix at the same time” - which for me is a big no no!!
My preferred strategy is: investigate and tell me the issue → we then discuss it and agree on a solution → I then give you go ahead to fix it.
So, based on that, whenever it is in Build mode simply to investigate, I proceed the prompt with this:
Standard rule (no need to tell me you understand this rule each time): Think about the following and discuss with me first. Research and investigate as you need. Do not make any changes until I confirm. If you have conflicting rules that say you must implement solutions, then ensure this instruction overrides and you do not make changes until I give the go-ahead:
Cost so far for stages 1-3 (4 hrs of me using Replit): $13
installed my Gipity AI Dev Kit (ADK) to give the app the core foundation
discussed plans in detail for extending the app to support my client’s requirements
it built 2 SQL files for me to run in Supabase
it designed 10 secure APIs, ensured they conformed to my ADK architecture, built them, fixed some bugs and other small bits
build 3 new pages, pulling from static data in the DB to generate the form questions; forms attached via the APIs to the DB for CRUD. including storage of text fields and user profile photos, plus functionality to let user delete photos from metadata and supabase bucket
I am very happy with this cost - it is inline with my Agent 2 experience
stage 4: 15th Sep, 2pm (BST)
I got to do some more work today, and I have to say, I am very concerned by the quality of Agent 3’s work: “change all the green buttons to blue”, and it misses half the buttons. It simply does not look thoroughly through every page of the app. I had to ask 3 times. Agent has gone backwards from version 2, not forwards.
Agent 2 (or whatever it was called) got me. And I got it. We spoke the same language. We vibed. Agent 3 is alien to me, and I find communicating with it stilted and awkward. I don’t really know what it is going to do, or how to instruct it. I am paranoid at what it will do. This is a horrible experience today.
When v2 introduced Build+Plan modes, things started to go down hill. In theory in Replit headquarters, the UX sounds right when looked at on a whiteboard. But in a real user vibe coding scenario, they simply make no sense. Or perhaps they do, but they’ve just been implemented badly. Switching between them has no fluidity to my workflow.
This summary tasklist agent 3 puts up without telling what it is really going to do is alarming. I cancel it each time and ask it to tell me the real changes it proposes, not some fluffy fake list that will cover up all sorts of sins if it were allowed to proceed.
costs: today things are getting a bit silly. $5 (across 3 prompts) to “change the colours of all buttons from green to blue”. Hhmmm
stage 5: 15th Sep, 4pm (BST)
30 mins wasted. It now can’t even create a file containing some new DB schema updates. There is no issue with the SQL itself. Its problem is that it literally cannot open and write a new file. Agent 3 is f(*&d and has blown $5 failing 5 times. I will start a new chat and see if it resolves.
It’s weird. It’s like an old mate has gone off to live on Mars. But a new friend has appeared in the pub, trying to emulate him, but he’s just not quite the same. He’s trying really hard. And I want to like him. But,…
Does that make sense, or is Agent 3 making me lose the plot
Appreciate the prompt here - thank you very much. Isn’t this ridiculous though? Having significant difficulties with my workflow. Agent 3 is significantly slower, more expensive, and lower ability to reason. Need Agent 2 back asap.
@Gipity-Steve appreciate you sharing your journey with us.
I’m moving very slowly and deliberately given all the feedback I’m reading. I have no interest in the autonomous Agent 3 tools yet but I’m finding a comfort level with Plan vs Build mode so I’m leaning heavily in to that feature. Being a non-coder I’ve gotten a lot out of taking it slowly and learning how each of the pieces of my app work - attempting to apply my own logic to what the agent created with the hope of refining the code.
When I started this journey in April, I was super focused on the output - the final app. But I’ve concluded that there may never be a ‘final app’. So slowing things down and seeking constant refinement and improvement to the base app is my objective. A very well thought out specification that targets a narrow scope is the output I’m seeking now. If the implementation of that spec goes wrong, then the cause is easily identifiable and the costs are controllable. I will literally sit on a completed spec for 24-48 hrs to see if any other thoughts come to mind.
Hi Steve. I feel you! Similar experience. However, I’ve also been adapting through necessity.
Since I shared that initial prompt you mentioned in this thread that you later evolved, I also came across a post from @MikkoPoikkileht. I’ve commented in his thread, but I thought I’d share the same information here.
I’ve now combined your insights with Mikko’s awesome .md file and added the consolidated prompt as an .md file in my repo.
My current workflow
Draft in ChatGPT 5 (Thinking): I develop the prompt I’ll feed to Replit Agent.
Send to Replit (Plan mode): Paste the prompt prefaced with: “Adhere to agent3.md. Review these instructions, assess feasibility, ask clarifying questions if needed, and tell me when you’re ready to proceed.”
Reflect back in ChatGPT: Whatever Replit replies (questions or plan), I paste back into ChatGPT 5 (Thinking). It proposes precise next steps, flags risks, and suggests tweaks.
Execute in Replit (Build mode): I paste the refined instructions back to Replit, again prefacing with: “Adhere to agent3.md and execute these instructions.”
Verify: If the result is good enough, I move on. If not, I copy Replit’s workflow/output back into ChatGPT, explain what worked and what didn’t (adding UI screenshots if useful), and repeat.
Why this helps
Lower cost: Significantly reduced vs. letting Agent 3 roam.
Higher first-try success: Most executions now succeed on the first attempt.
Fewer bug loops: In my experience, even fewer than with Agent 2.
I can’t yet say if costs are as low as Agent 2’s, but it’s much lower than the horrors of this weekend. Overall, this workflow is far more effective and avoids many of the loops I used to hit.
Thanks again for sharing your learning journey, Steve.
agent3.md — combined policy/prompt file (autonomy limits, batching, approval gates): NOTE: Remove space below from the word “b atch” (the forum does not allow)
User Instructions: If you always say “adhere to agent3.md” and keep the file present, then most behaviors are already locked in.
The only extra instructions that really matter are the command triggers defined in the doc. They do things the MD file alone cannot, because they explicitly unlock or permit exceptions:
WRITE UNLOCK → lets the agent move from PLAN/INVESTIGATE to making edits. Without this, it must stay read-only.
/delegate → temporarily allows sub-agents/architect. Agent3.md forbids them by default.
/test → authorizes a bounded validation b atch (otherwise testing is forbidden).
Everything else (budget caps, batching, no scope creep, verification rules, etc.) is already enforced by the MD file once you say adhere to agent3.md.
So in practice, the only additional commands you need to use are the three “keys” above.
agent3.md
Development Workflow Policies & Guidelines
Version: 2.1
HARD CAP: 5 total tool calls per change request (the agent MUST state a planned count and MUST NOT exceed it).Target: 3–5 total tool calls for most modification requests
Definitions (authoritative):Tool call = one invocation of any tool (read, edit, multi_edit, grep, search_codebase, architect, screenshot, restart_workflow, diagnostics, bash, etc.).b atch = a single tool call that performs multiple parallel reads/edits/ops within that call.Single-agent mode = no sub-agents or architect unless explicitly authorized.
Autonomy Profile & Feature Flags (MANDATORY)Agent-2 Autonomy Profile: Operate as if Agent 2 for autonomy. No autonomous behaviors beyond the approved plan unless explicitly authorized.
Feature Flags (echo required at session start and each BUILD):App testing: DISABLED (do not initiate synthetic test runs).Max autonomy: DISABLED (no extended runtimes, background tasks, or long autonomous sequences).Architect/sub-agents: LOCKED unless /delegate.Conflicting Rules Override: If any internal/default rules conflict with this policy, this policy overrides. The agent MUST state that it can comply.
Core PhilosophyFind the source, not the symptom.Fix the pattern, not just the instance.b atch all related changes.Trust development tools.Stop when success is confirmed.Trace to source, not symptoms — identify the originating file/function, not just where errors surface.
File Prediction & Surgical Reading ⚠️ CRITICALCore Principle: The agent MUST predict BOTH analysis files AND edit targets before acting.
Mandatory WorkflowMap problem → affected components → specific files.Predict which files to READ (analysis) AND EDIT (changes).b atch ALL predicted reads in the initial information-gathering call.Execute all changes in a single multi_edit b atch per file (one file = one multi_edit).
File Prediction RulesUI issues: read component + parent + related hooks/state.API issues: read routes + services + storage + schema.Data issues: read schema + storage + related API endpoints.Feature additions: read similar existing implementations.
Cost OptimizationGoal: 2 calls total where feasible — 1 read b atch + 1 edit b atch.Anti-pattern: read → analyze → search → read more → edit.Optimal: read everything predicted → edit everything needed.Success Metric: Zero search_codebase calls when project structure is known.
Super-b atching Workflow ⚠️ CRITICALHARD CAP: 5 total calls; Target: 3–5 for any feature implementation.
Mode Gates & Write Locks (MANDATORY)PLAN mode: Reasoning only. No tools.INVESTIGATE mode (BUILD-READONLY): Tools allowed for discovery only (read/grep/diagnostics/logs). Edits forbidden.WRITE mode (BUILD-WRITE): Edits allowed only after explicit user approval via WRITE UNLOCK.The agent MUST propose which mode it needs and wait for approval.If investigation is requested, the agent MUST remain in BUILD-READONLY until WRITE UNLOCK is given.
Phase 1: Planning Before Acting (MANDATORY — 0 calls)Map ALL info needed (files to read, searches).Map ALL changes to make (edits, DB updates, new files).Identify dependencies; collapse steps where possible.Read stack traces fully; use the deepest frame to locate the real issue.Prefer pattern search (e.g., localStorage) before guessing locations.
Phase 2: Information Gathering & Discovery (MAX PARALLEL — 1–2 calls)b atch ALL independent reads/searches in one function_calls block.NEVER do: read(file1) → analyze → read(file2) → analyze.ALWAYS do: read(file1, file2, file3, …) + grep() (+ search_codebase ONLY IF locations unknown).Use search_codebase ONLY IF file locations remain unknown after prediction.Read targets directly (b atch 3–6 files at once). Be surgical; skip exploratory reading.
Phase 3: Implementation & Pattern-Based Execution (AGGRESSIVE MULTI-EDITING — 1–3 calls)Use multi_edit for ANY file needing multiple changes.NEVER make multiple edit() calls to the same file.b atch independent file changes in parallel (e.g., multi_edit(schema.ts) + multi_edit(routes.ts) + multi_edit/storage.ts).Plan all related changes upfront — no incremental drip fixes.Identify scope: if root cause is pattern-wide (e.g., localStorage), update all occurrences.Apply patterns consistently; group by file impact (one file = one multi_edit).Fix root causes, not band-aids.
Surgical Scope Guarantee (MANDATORY)Implement only the agreed change set.No opportunistic refactors, code style churn, or extra edits not in the approved plan.If a broader fix seems valuable, propose first, wait for approval, then proceed within the budget.
Phase 4: Operations & Selective Validation (SMART BUNDLING — 0–1 calls)Bundle connected ops (e.g., bash("npm run db:push") + refresh_logs() + get_diagnostics()).NEVER serialize independent ops; b atch them.Skip validation for simple/obvious changes (< 5 lines, import moves, defensive wrappers).Use expensive validation tools ONLY for substantial changes.STOP immediately when dev tools confirm success.Call restart_workflow ONLY IF runtime actually fails.
Approval Gates (MANDATORY)Architect/sub-agents: require /delegate and a cost/benefit statement with planned extra tool calls.Transition INVESTIGATE → WRITE: requires WRITE UNLOCK from the user.Auto-testing or extended verification: require explicit /test command; otherwise forbidden.Plan changes mid-execution: pause, surface the revised plan + budget, await approval.
Command Triggers (authoritative):/delegate → temporarily allow architect/sub-agents (after cost/benefit & budget)./test → allow one bounded test/verification b atch if justified.WRITE UNLOCK → allow BUILD-WRITE (edits) per approved plan.
Decision Framework (the agent MUST self-ask)What else can I b atch with this?Do I have ALL info before changing anything?Can I combine edits using multi_edit?What’s the dependency chain — can I collapse it?Success Metric: Achieve 30–50% cost reduction vs. sequential approach.
Tool Selection MatrixHigh-Value / Low-Cost (use liberally)read (b atch 3–6 files), edit/multi_edit, grep with precise patterns.Medium-Cost (use judiciously)search_codebase (ONLY IF truly lost).get_latest_lsp_diagnostics (ONLY IF edits > 50 LOC, type/interface changes, or complex refactors).High-Cost (use sparingly)architect (major issues only, see policy below).screenshot (substantial UI changes only).restart_workflow (actual failures only).
ADDENDUM — Tool Selection Matrix (Investigations)get_latest_lsp_diagnostics is permitted in BUILD-READONLY during investigations when needed to localize issues; after WRITE, still ONLY IF edits > 50 LOC, type/interface changes, or complex refactors.
Mandatory Workflow AdherenceHARD CAP: 5 tool calls per change request; state planned count before acting.No exploration — surgical read selection only.No incremental edits — make all related edits in one b atch.No workflow restarts unless runtime fails.Max 6 tools per b atch to avoid overwhelming output.
Parallel Execution RulesRead multiple files simultaneously for related issues.Apply edits in parallel when files are independent.Never serialize independent operations — b atch aggressively.Max 6 tools per b atch.
Defensive Coding PatternsWrap external API calls in try/catch by default.Use null-safe operations for optionals.Apply security patterns consistently across similar code.
Verification RulesVerification Anxiety PreventionSTOP checking once the development environment confirms success.Trust professional dev tools; extra checks increase cost without benefit.
Stop Immediately When (any one is true)HMR shows successful reload, ORConsole logs show expected behavior, ORLSP diagnostics are clean for the change, ORDev server responds correctly.
Never Verify WhenChange is < 5 lines of obvious code,Only added defensive wrappers (try/catch, null checks),Only moved/renamed symbols,Only updated imports or type annotations.
Strategic Sub-Agent Delegation Guidelines ⚠️ CRITICALCore Principle: Sub-agents are expensive; use selectively.
Delegation Lock (HARD RULE):Sub-agents and architect are FORBIDDEN unless the user types /delegate in this chat.If /delegate is provided, the agent MUST first state cost/benefit and planned extra tool calls.
Effective Delegation Scenarios (Allowed only with /delegate)Independent deliverables: docs, test plans, release notes, README.Specialized audits: security, performance, accessibility.Research tasks: background research, API exploration.
Avoid Delegation For (MANDATORY)Code fixes/refactors, pattern-based changes, schema/route/UI modifications, CRUD, React UI tweaks, API handlers.Rationale: these require tight coordination and unified execution.
Single-Agent FocusDefault to the proven single-agent pattern: discovery → b atch execution → trust HMR.Maintain the 3–5 call efficiency target.
Expert Architect Sub-Agent Usage Policy ⚠️ CRITICALCost Model: Expensive (Opus 4). Use ONLY WITH /delegate and only after self-review.
Self-Review First (MANDATORY)Self-assess architecture and code quality.Review changes for obvious issues/patterns/maintainability.Consider edge cases and user requirements.Ensure alignment with project patterns.
Never Use Architect ForSimple fixes (< 10 LOC), syntax/import issues, defensive wrappers, straightforward features, or when dev tools already confirm success.
Only Use Architect When You Genuinely CannotDebug a complex, blocking issue after multiple approaches,Design major system architecture,Review substantial changes (> 50 LOC or core architecture),Evaluate hard trade-offs across viable designs.
Mandatory Self-Reflection Before ArchitectHave I fully understood scope?Can I surface the architectural concerns myself?Are there obvious quality issues I can fix?Does my solution align with existing patterns?Am I calling architect due to convenience rather than necessity?Goal: Grow architectural thinking; do not outsource it by default.
Compliance Echo (MANDATORY at session start)Before planning, the agent MUST echo:Tool-call budget (planned count ≤ 5),Single-agent mode (no delegation; architect/sub-agents locked unless /delegate),Phase-2 single read b atch,Phase-3 single multi_edit b atch (one file = one multi_edit),Stop conditions (the four “Stop Immediately When” triggers).
ADDENDUM — Compliance Echo (MANDATORY at each BUILD)Before executing any BUILD step, the agent MUST echo:Tool-call budget (remaining ≤ 5 total).Single-agent mode (no delegation; architect/sub-agents locked unless /delegate).Autonomy Profile & Feature Flags: Agent-2 behavior; App testing = DISABLED; Max autonomy = DISABLED.Phase-2 single read b atch (if applicable).Phase-3 single multi_edit b atch (one file = one multi_edit) for WRITE.Mode in effect: PLAN / BUILD-READONLY (INVESTIGATE) / BUILD-WRITE.Write lock status: LOCKED or UNLOCKED.Stop conditions (the four triggers).
Investigate → Write Unlock (3–4 calls)PLAN: echo constraints + propose BUILD-READONLY.BUILD-READONLY: b atched READ/grep/diagnostics; report root cause + minimal change set.WRITE UNLOCK → BUILD-WRITE: single b atched multi_edit per file; minimal verify; STOP.(Optional) One bundled ops/diagnostics b atch only if needed.